1、简介
定义:Log-Structured Merge Tree,简称 LSM-Tree.
遥想当年,谷歌发表了 “BigTable” 的论文, 它所使用的文件组织方式,这个方法更一般的名字叫 Log Structured-Merge Tree。
LSM是当前被用在许多产品的文件结构策略:比如 Apache HBase, Apache Cassandra, MongoDB 的 Wired Tiger 存储引擎, LevelDB 存储引擎, RocksDB 存储引擎等、 SQLite,甚至在mangodb3.0中也带了一个可选的LSM引擎(Wired Tiger 实现的)。
LSM 有趣的地方是他抛弃了大多数数据库所使用的传统文件组织方法,LSM把一棵大树拆分成N棵小树,它首先写入内存中,随着小树越来越大,内存中的小树会flush到磁盘中,磁盘中的树定期可以做merge操作,合并成一棵大树,以优化读性能。将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘,不过读取的时候稍微麻烦,需要合并磁盘中历史数据和内存中最近修改操作,所以写入性能大大提升,读取时可能需要先看是否命中内存,否则需要访问较多的磁盘文件。
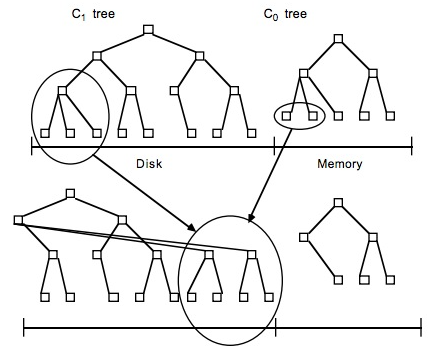 磁盘和内存中的树合并
磁盘和内存中的树合并简单地说,LSM 的设计目标是提供比传统的 B+ 树更好的写性能。LSM 通过将磁盘的随机写转化为顺序写来提高写性能 ,而付出的代价就是牺牲部分读性能、写放大(B+树同样有写放大的问题)。
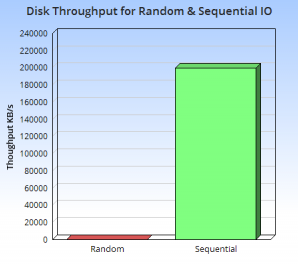 磁盘随机读写和顺序读写性能对比
磁盘随机读写和顺序读写性能对比从上图中我们可以直观的看出来,顺序读写磁盘(不管是SATA还是SSD)快于随机读写主存,而且快至少N个数量级。这就要我们在设计的时候要避免随机读写,最好是顺序读写。通常LSM-tree适用于索引插入比检索更频繁的应用系统。 而LSM-tree通过滚动合并和多页块的方法推迟和批量进行索引更新,充分利用内存来存储近期或常用数据以降低查找代价,利用硬盘来存储不常用数据以减少存储代价。
2、读性能优化
- 二分查找: 将文件数据有序保存,使用二分查找来完成特定key的查找。
- 哈希:用哈希将数据分割为不同的bucket
- B+树:使用B+树 或者 ISAM 等方法,可以减少外部文件的读取
- 外部文件: 将数据保存为日志,并创建一个hash或者查找树映射相应的文件
所有的方法都可以有效的提高了读操作的性能,都强加了总体的结构信息在数据上,数据被按照特定的方式放置,可以很快的找到特定的数据,但是却对写操作不友善,让写操作性能下降。更糟糕的是,当我们需要更新hash或者B+树的结构时,需要同时更新文件系统中特定的部分,这就是上面说的比较慢的随机读写操作。
3、权衡读写
LevelDB 为代表的 LSM 存储引擎实现的是优化后的 LSM,LevelDB 的写速度非常快,写操作主要由两步组成:
- 写日志并持久化(Append Only)。
- Apply 到内存中的 memtable(SkipList)。
基本的思路与原始的LSM类似,memtable 写“满”后,会转换为 immutable memtable,然后被后台线程 compaction 成按 Key 有序存储的 sst 文件(顺序写)。由于 sst 文件会有多个,所以 LevelDB 的读操作可能会有多次磁盘 IO(LevelDB 通过 table cache、block cache 和 bloom filter 等优化措施来减少读操作的磁盘 IO 次数)。
参考链接: http://www.benstopford.com/2015/02/14/log-structured-merge-trees/