自然语言处理( Natural Language Processing, NLP)是计算机科学领域与人工智能领域中的一个重要方向。nltk (Natural Language Toolkit),自然语言处理工具包,在NLP领域中,最常使用的一个Python库。
nltk是一个开源的项目,包含:Python模块,数据集和教程,用于NLP的研究和开发;NLTK由Steven Bird和Edward Loper在宾夕法尼亚大学计算机和信息科学系开发。NLTK包括图形演示和示例数据。其提供的教程解释了工具包支持的语言处理任务背后的基本概念。
一、安装
NLTK requires Python versions 3.5, 3.6, 3.7, 3.8, or 3.9
Mac/Unix的环境下: pip install –user -U nltk
windows环境下:http://www.python.org/downloads/ 下载后安装,也可以在cmd窗口下通过pip命令按照。
二、语料下载
我们使用windows环境,在cmd命令下输入python,回车,进去python命令交互窗口,然后输入一下代码;也可以是在IED里输入一下代码,之后运行脚本。
import nltk #然后下载语料库 nltk.download()
代码运行后会弹出窗口如下,按需下载,我最初不确定自己会用什么语料,所以双击了all。整个下载完占用3个G左右的空间。
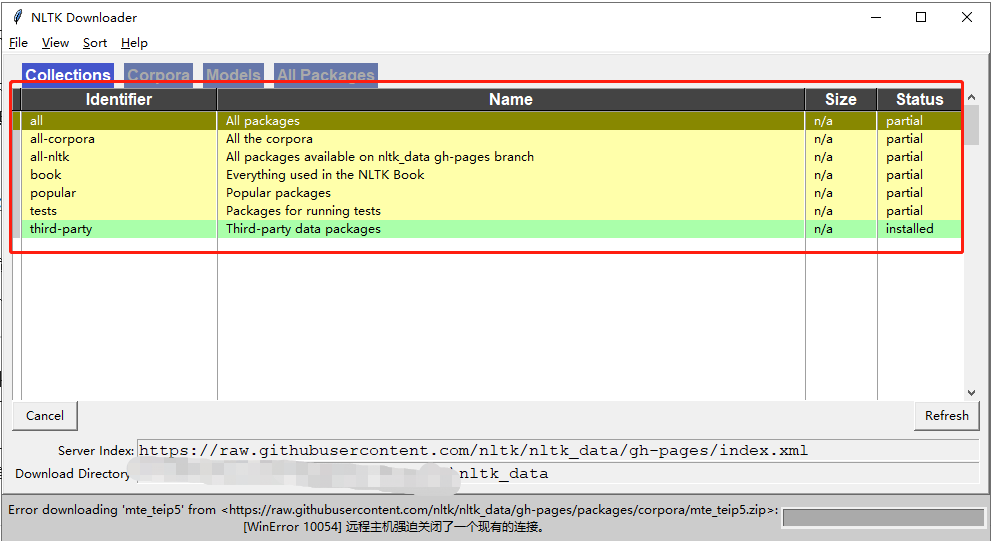
其中corpora为语料库,也可以下载自己需要的语料库:http://www.nltk.org/nltk_data/
corpora中有好多文章和字典,wordnet是面向语义的词典,names里包含了好多名字,stopwords包含了可忽略的语法上的高频词汇,words包含平时常用的单词可用来做拼写检查,还有city_database,webtext,unicode_samples等语料。
wordnet语料库:wordnet是普林斯顿大学创建的语义词典,特点是其中包含了大量的单词间的联系,可以看作是一个巨大的词汇网络。
词与词之间的关系可以为同义,反义,上下位(水果-苹果),整体部分(汽车-轮胎)。建立关系是大脑学习的首要过程,知识的脉络必定可达,孤立点会被遗忘。
wordnet API:http://www.nltk.org/howto/wordnet.html
三、语料使用
使用的时候直接import即可,如
from nltk.corpus import gutenberg from nltk.corpus import stopwords
使用 wordnet
from nltk.corpus import wordnet as wn
from nltk.corpus import wordnet as wn
print(wn.synsets('food'))
# 输出:[Synset('food.n.01'), Synset('food.n.02'), Synset('food.n.03')]
注: synsets()用来查询一个单词,返回结果是Synset数组,一个Synset由 单词-词性-序号 组成