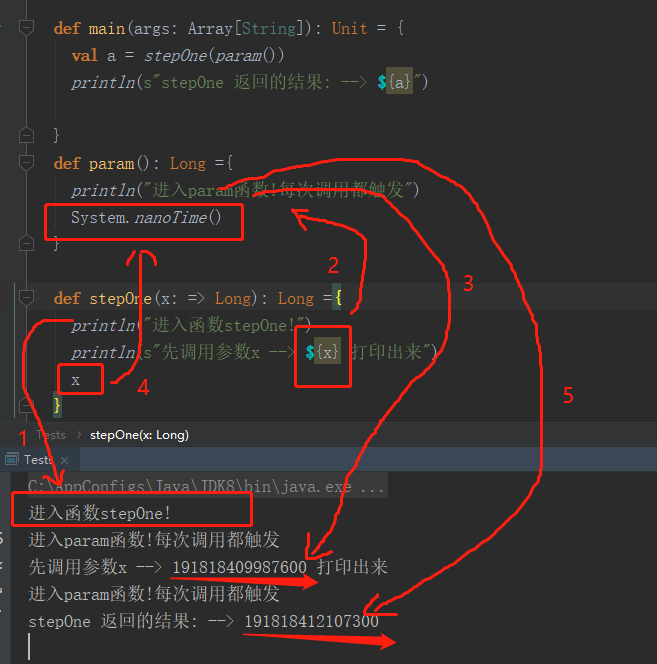
val conf = new SparkConf()
conf.setMaster("local").setAppName("brocast")
val sc = new SparkContext(conf)
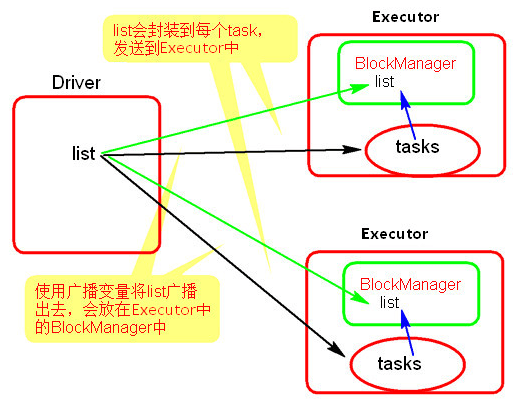
val list = List("hello xasxt")
val broadCast = sc.broadcast(list)
val lineRDD = sc.textFile("./words.txt")
lineRDD.filter { x => broadCast.value.contains(x) }.foreach { println}
sc.stop()
第一个参数应是数值类型,是累加器的初始值,第二个参数是该累加器的命字,这样就会在spark web ui中显示,可以帮助你了解程序运行的情况。
val conf = new SparkConf()
conf.setMaster("local").setAppName("accumulator")
val sc = new SparkContext(conf)
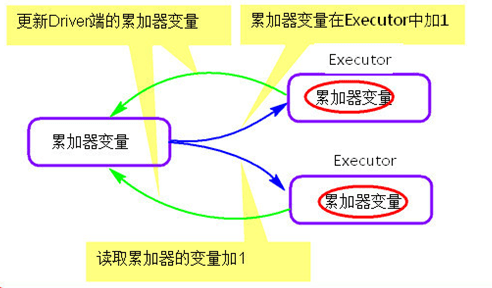
val accumulator = sc.accumulator(0)
sc.textFile("./words.txt").foreach { x =>{accumulator.add(1)}}
println(accumulator.value)
sc.stop()
val accum= sc.accumulator(0, "Error Accumulator")
val data = sc.parallelize(1 to 10)
//代码和上方相同
val newData = data.map{x => {...}}
//使用cache缓存数据,切断依赖。
newData.cache.count
//此时accum的值为5
accum.value
newData.foreach(println)
//此时的accum依旧是5
accum.value