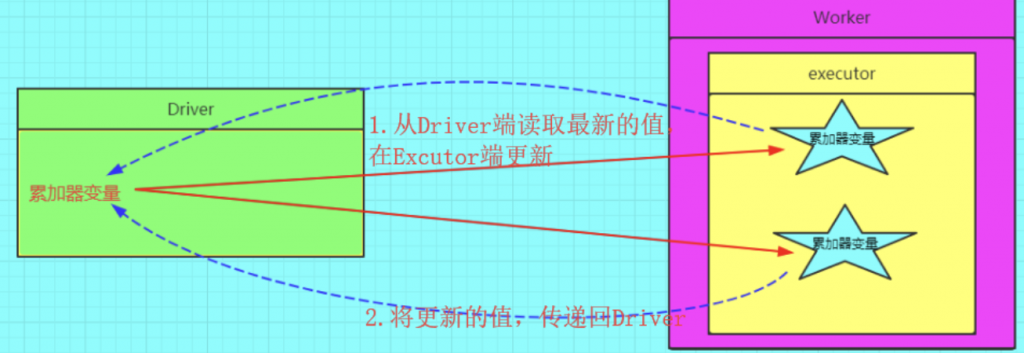
spark Accumulator AccumulatorV2 累加器是Spark的核心数据结构之一 — Spark的三大核心数据结构:RDD、累加器(只写不读)、广播变量(只读不写),累加器在不同的spark版本中有不一样的具体实现逻辑;而累加器的基本逻辑过程如下
- 自定义变量在Spark中运算时,会从Driver中复制一份副本到Executor中运算,但变量的运算结果并不会返回给Driver,所以无法实现自定义变量的值改变,一直都是初始值,所以针对这个问题,引入了累加器的概念;
- 系统累加器longAccumulator和自定义累加器(extends AccumulatorV2[类型,类型])实际都是两步,new累加器,然后sc.register注册累加器;
- 先在Driver程序中创建一个值为0或者空的累加器对象,Task运算时,Executor中会copy一份累加器对象,在Executor中进行运算,累加器的运算结果返回给Driver程序并合并Merge,得出累加器最终结果
- 累加器.add(元素);具体对元素的操作包括数据sum、增加、删减、筛选等要求,都可以写在自定义累加器的.add()方法中。
Spark API
- spark API的地址都可以在该网址中找到: https://spark.apache.org/docs/
- 点击想要看到的版本,页面打导航栏有 API Docs ,点击想要了解的语言名称即可,例如点击 Scala,则进入对应的API地址 : https://spark.apache.org/docs/2.0.0/api/scala/index.html#org.apache.spark.package
- 我们查看具体的类和方法的时候就特别注意一个单词 【Deprecated】,它有时候会出现类声明的最开始 Annotations,或者直接在具体的方法说明中出现。当出现这个单词的时候就意味着这个类或者方法在以后的版本中要慢慢被弃用或者替代了
Accumulator 和 AccumulatorParam
Spark1.x 中实现累加器需要用到类 Accumulator和 AccumulatorParam。以spark1.6.3为例,内置数值类型的累加器用Accumulator类,而自定义累加器需要继承接口AccumulatorParam ,并实现相应的方法,而在2.0版本之后这个方式开始不再推荐使用了。
// 在类的声明中出现了如下的说明,也就是该类将被 AccumulatorV2 所替代。
Annotations @deprecated
Deprecated (Since version 2.0.0) use AccumulatorV2 trait AccumulatorParam[T] extends AccumulableParam[T, T]While this code used the built-in support for accumulators of type Int, programmers can also create their own types by subclassing AccumulatorParam. The AccumulatorParam interface has two methods: zero for providing a “zero value” for your data type, and addInPlace for adding two values together. For example, supposing we had a Vector class representing mathematical vectors, we could write:
object VectorAccumulatorParam extends AccumulatorParam[Vector] {
def zero(initialValue: Vector): Vector = {
Vector.zeros(initialValue.size)
}
def addInPlace(v1: Vector, v2: Vector): Vector = {
v1 += v2
}
}
// Then, create an Accumulator of this type:
val vecAccum = sc.accumulator(new Vector(...))(VectorAccumulatorParam)AccumulatorV2
从spark2.0开始自定义累加器的实现不再提倡使用AccumulatorParam, 而是使用AccumulatorV2, 自定义类继承AccumulatorV2,并重写其固定的几个方法
- reset:用于重置累加器为0
- add:用于向累加器加一个值
- merge:用于合并另一个同类型的累加器到当前累加器
- copy():创建此累加器的新副本
- isZero():返回该累加器是否为零值
- value():获取此累加器的当前值
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("Application")
//构建Spark上下文对象
val sc = new SparkContext(conf)
//创建累加器
val sum = new MyAccumulator()
//注册累加器
sc.register(sum,"accumulator")
val rdd = sc.makeRDD(Array(1,2,3,4,5))
rdd.map(item=>{
sum.add(item)
}).collect()
println("sum = "+sum.value)
//释放资源
sc.stop()
}
//自定义累加器
class MyAccumulator extends AccumulatorV2[Int,Int]{
var sum = 0
//1. 是否初始状态(sum为0表示累加器为初始状态)
override def isZero: Boolean = sum == 0
//2. 执行器执行时需要拷贝累加器对象(把累加器对象序列化后,从Driver传到Executor)
override def copy(): AccumulatorV2[Int,Int] = {
val mine = new MyAccumulator
mine
}
//3. 重置数据(重置后看当前累加器是否为初始状态)
override def reset(): Unit = sum = 0
//累加数据
override def add(v: Int): Unit = {
sum = sum + v
}
//合并计算结果数据(把所有Executor中累加器value合并)
override def merge(other: AccumulatorV2[Int, Int]): Unit = {
sum = sum + other.value
}
//累加器的结果
override def value: Int = sum
}