![]()
flink是什么?
对于技术学习,无论是什么语言什么工具,对其介绍或者说学习最主要的途径就是官方网站和主要文档。其它任何地方的信息都是其官方网站的信息挪用。对flink的介绍在其官网上有下边一段话。
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
大概翻译一下: flink是一个用于对无界和有界数据流进行有状态计算的框架和分布式处理引擎,被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算, 即它是一个持高吞吐、低延迟、高性能的分布式处理框架
- 无界数据流:无界数据流有一个开始但是没有结束
- 有界数据流:有界数据流有明确定义的开始和结束
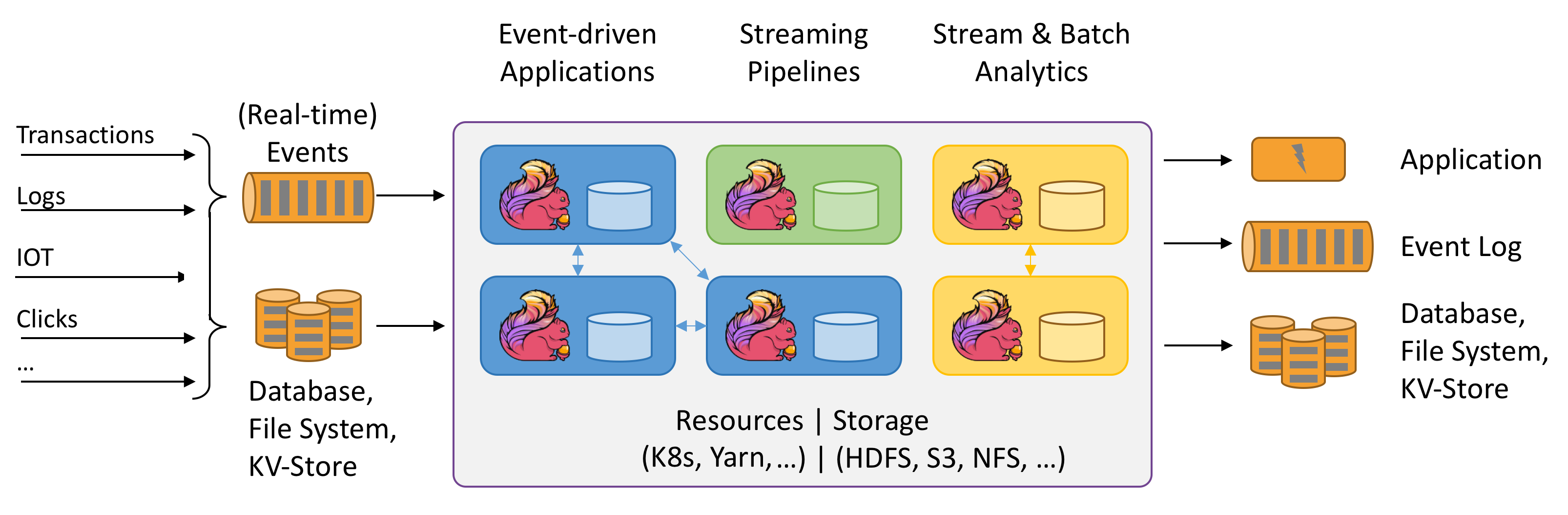
flink的特点
用一句话来概述特点就是,flink基于数据流的状态计算。而在其官网地址打开时有一张图也可以具体的体现其特点。事件驱动、流处理、流批一体
flink VS spark
在spark中,一切都是由批次组成的,离线数据是一个大批次,而实时数据是由一个一个无限的小批次组成的,本质是RDD,是数据集合,是有界的。
在flink中,一切都是由流组成的,离线数据是有界限的流,实时数据是一个没有界限的流,这就是所谓的有界流和无界流。

近期评论