场景描述:我们有很多文章需要进行分词处理,而文章存储的内容是带有html标签的;我们需要利用自定义的字典来对文章进行分词。这里我们使用ansj来自定义字典和停留词进行分词,同时还需要先用jsoup对文章的内容从html标签中提取出来。
1、环境说明
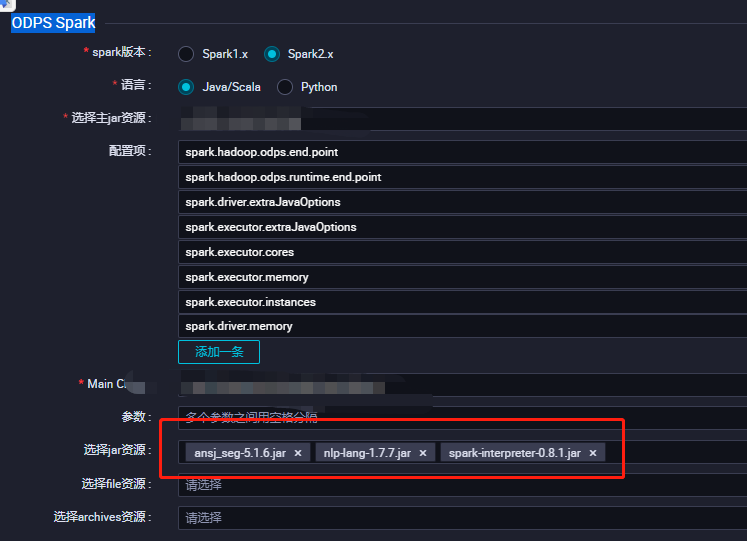
如果开发或者生成环境是自建的spark运行环境,记得通过maven或者gradle引入 ansj, 对应的版本需要根据您spark的版本去maven库检索并且maven检索到响应的jar包后可以拿到maven或者gradle的引入方式;如果读者用到了阿里云的MaxCompute计算引擎,在dataworks上搭建环境,则需要构建如下的ODPS Spark,把ansj_seg-**.jar, nlp-lang-**.jar, spark-interpreter-**.jar 加入到dataworks的生存环境中即可。
2、主要实现逻辑
第一步,先构建一个自定义的字典库,这个库的实现方式是多样的,可以通过预处理的代码生成一个文本文件,一行一个词的形式并把文件整个放到hdfs 或者其它对象存储的路径下,又或者把这些词放贷一张spark可以读取的表中;之后分词之前加载进来即可。
第二步,预加载自定义的词库初始化ansj的自定义词典;利用spark广播的方式,把自定义的词典广播出去。
第三步,利用广播的字典在每个分区里处理每一篇文章(分词之前去html标签)
笔者自定义词库是放到了hive表中,通过hive + sparksql的方式预处理生成的词库;而在加载词库生成自定义词典时的代码如下,之所以用flatmap是因为之前预处理的词库一行用逗号连接了多个词,如果读者是一行一个词直接用map处理即可。
返回自定义词典之后,把这个词典通过broadcast广播
/**
* 加载自定义词典
* @param spark
* @return
*/
def load_KeyWords(spark: SparkSession): Forest ={
//自定义词库的key名(可以任意定义)
val dicKey = "articleDic"
val keywords = spark.sql(s"select keywords from artile_keywords_table")
val words = keywords.rdd.filter(x => null != x).flatMap{row =>
row.getAs[String]("keywords").split(",").filter(x=> null != x && !x.trim.equals("") && !x.trim.equals("null") && x.trim.length > 1)
}.distinct().persist(StorageLevel.MEMORY_AND_DISK)
val word_num = words.count()
words.collect().foreach(word => DicLibrary.insertOrCreate(dicKey, word.trim, DicLibrary.DEFAULT_NATURE, DicLibrary.DEFAULT_FREQ))
log.info(s"user dict words is ${word_num}")
words.unpersist()
DicLibrary.get(dicKey)
}
val user_dict = load_KeyWords(spark)
//广播自定义词典
val userDic = spark.sparkContext.broadcast(user_dict)
加载所有的文章,利用字典分词,文章加载及处理分词的主要逻辑代码如下,查询hive表中文章的id,标题和内容,通过mapPartitions算子把每一篇文章都分词
// 文章的id, 标题,内容
val sql=s"SELECT a.article_id,a.title, b.content from article_content a"
val df = spark.sql(sql).persist(StorageLevel.MEMORY_AND_DISK)
res.write.mode("overwrite").saveAsTable(ARTICLE_SPLIT_WORDS_TB)
val res = df.rdd.mapPartitions(
iter => {
iter.map(line =>
(line.getAs("article_id").toString.trim.toLong, dict_parse_words(userDic.value, line.getAs[String]("title") + line.getAs[String]("content") ))
)
}
).toDF("article_id","words")
分词的时候还自定义了一些需要过滤的词性以及停留词(停留词没有做过多的处理,因为项目有其它业务逻辑的应用所有尽可能多的留下了全部的有效分词)
def dict_parse_words(dic: Forest=DicLibrary.get(DicLibrary.DEFAULT), text: String): Map[String, Int] ={
//分词准备
val stop = new StopRecognition()
stop.insertStopNatures("w")//过滤掉标点
stop.insertStopNatures("t")//过滤掉时间
stop.insertStopNatures("m")//过滤掉m词性
stop.insertStopNatures("null")//过滤null词性
stop.insertStopNatures("<br />")//过滤<br />词性
stop.insertStopNatures("v") // 过滤动词
stop.insertStopNatures("q") // 过滤量词
stop.insertStopNatures("u") // 过滤助词
stop.insertStopNatures("y") // 过滤语气词
stop.insertStopNatures(":")
stop.insertStopNatures("'")
stop.insertStopWords("<p>")
stop.insertStopWords("<td>")
stop.insertStopWords("align","<",">","text", "style", "strong", ")","(")
// 利用jsoup提取html的内容
val _text = jsoup.Jsoup.parse(text)
val _parse = DicAnalysis.parse(_text.body().text(), dic).recognition(stop)
val words = _parse.getTerms.toArray.toList.filter(x =>
x.asInstanceOf[Term].natrue().natureStr.equals(DicLibrary.DEFAULT_NATURE) &&
x.asInstanceOf[Term].getRealName.length > 1 &&
!Tools.isNumber(x.asInstanceOf[Term].getRealName) &&
!x.asInstanceOf[Term].getRealName.trim.equals(""))
words.map(x => x.toString.split("/")(0)).groupBy(l=>l).map(t => (t._1,t._2.length))
}

近期评论