说在前面的话
- python在自身历史版本中主要是python2和python3。我们不去表述各种的python实现,用C(CPython)\C++(Pyston)\Java(Jython)\C#(IronPython)\Ruby\JS都有, 我们只去说一下基于python3的最基础的使用和应用。当然很多的教程是以python2来写的,如果我们遇到其实并不影响我们去学习。
- 浏览器主要是Chrome
一钱思路
- 拿到http://**.com/path/to/page 的地址, 将地址在浏览器(Chrome)中打开
- 在浏览器加载完地址且能看到你想看到的页面后,按F12 或者 直接在页面 右键=> 点击检查 ,页面会在某一个侧(默认是页面的右侧或者下侧)弹出如下图的 开发者工具, 图中的标红的箭头、 Elements、Network很关键,几乎是囊括了web爬虫所需的所有前置条件。
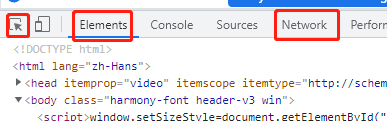
- 一般是箭头和Elements组合来使用,使用的目的是什么?就是确定你要爬取的数据在页面的什么地方。 步骤是:先点击Elements,它的紧下侧会有强调横线出现,同时整体下方出现的是html源码页面,看到<!DOCTYPE html> 就是了; 然后点击最左侧的箭头,箭头的颜色会变成蓝色或者颜色加重,随后把鼠标慢慢挪到真正的页面内容上,就会发现不一样了,这个时候html 源码页面的光标会随着你的鼠标在实际的可见页面移动而移动。而且点击一下实际可见页面的随意内容,html源码的光标就会立刻停在源码的位置, 实际页面不会发生变化。
- Elements + 箭头的 页面定位操作, 每一次定位 箭头都要从新点击一次。
- 对于Network点击后看到的是页面加载时的所有页面接口,如果说Elements + 箭头对应的静态页面内容的话,Network对应的就是动态加载的数据;明确哪些数据是有哪个接口提供的以及这个接口需要什么参数、cookie等关键性的请求依据都是从Network获取的
- 如果在浏览器中输入的地址没有得到具体的页面,而是一个登陆页面,此时就需要箭头+Elements+Network一起上了, 先用箭头+Elements明确登陆页面的需要输入的元素在哪里,在葱Network中确定登陆接口;如果登陆需要验证码还要从第三方的接口或者验证码的破解来辅助登陆。
- 以上都是基于浏览器可以直接看到数据的情况,如果页面是纯粹的动态加载,那么就要涉及到对页面js的逆向工程及更深层次的技术,此处不做深入谈论; 而如何确定页面是不是动态加载的呢?这个可以在Elements中找到答案, 去Elements的html页面查询真实页面的数据项,如果查不到基本上可以确定数据项是动态加载的, 这个时候需要去Network中找跟我们地址url对应到接口来确定页面数据是由哪个接口来动态提供的。如果只是简单需求可以用Selenium解决这个问题
二两概念
- request 和 response是什么?
request :可以通俗理解成对页面发起网络请求response: 可以通俗理解成对网页请求后,响应返回的数据request和response在很多类或者方法定义的主要关键字,又或者是约定成俗的写法; 在爬虫任务进行时的信息数据的两个不同的流向代表。
- 能抓取怎样的数据?
网页文本、图片、视频、二进制流
- 解析方式有哪些?
直接处理、json解析、正则表达式、beautifulsoup、pyquery 、 Xpath
- 怎样解决js渲染的问题?
分析Ajax请求、用selenium / webdriver、Splash、Pyv8
三分技术
- requests (请求页面)
- requests是python的网络请求库,在很多的教程中也会提到python的内置库 urllib。
- 其实两者的本质没有什么区别,都可以模拟网页请求,对网页进行GET 和POST请求。
- requests是对urllib的进一步封装,且requests使用起来相对比较更加便捷。
- urllib通俗教程地址: https://www.runoob.com/python3/python-urllib.html
- requests 官方文档: https://docs.python-requests.org/en/latest/user/install/ 。当页可以看到安装方式。在页面的左侧有一个 Useful Links, 它下方有一个 Quickstart, 可以看到具体的操作教程。
- xpath (解析页面)
- xpath是一门在 XML 文档中查找信息的语言,说的通俗点就是我们爬取的网页是一种有着基本款式和样式的本文信息, xpath就可以解析这些信息,从而取到我们想要的内容。
- xpath是一种技术,在python中常用的库是 lxml
- 为啥要用xpath先在页面搞一下? 因为我们不知道页面是什么样的,那么爬取到数据后我们也没有办法知道取哪里的信息为我所用,所有要运行所有的爬取程序之前先用浏览器目测一下具体哪些内容可以怎么接下下来。
- xpath入门连接: https://www.runoob.com/xpath/xpath-tutorial.html
- 实际使用中, 以chrome浏览器为例,chrome浏览器是有自己的插件的,这个插件叫做XPath Helper, 它的作用是直接从页面可以快速的获取页面中我们想要的内容的xpath路径。如果是其它浏览器的基本操作前边也都是一样的,只是需要人工来找到想要内容的xpath路径,这样就需要爬虫代码的编写者非常熟悉xpath语法了。
- 无论是否是chrome浏览器,在看一个页面的元素xpath路径时都是有一个基本的步骤的
1、用浏览器(IE 和 chrome为例)打开想要爬取的页面地址 2、页面上任何位置 右键 --> 检查 (检查元素) 或者直接按 F12 (不同浏览器说辞可能不一样,但是含义是相同的),会看到浏览器的下方或者右侧弹出如下两张图的界面,最左侧的箭头+方块的图标选中后就可以在页面选择元素了,也可以直接在弹出的界面中的页面源码中选择元素
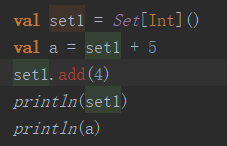
import requests
from lxml import etree
if __name__ == __main__:
headers = {
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36
}
url = https://anqiu.58.com/ershoufang/
page_text = requests.get(url = url,headers = headers).text
tree = etree.HTML(page_text)
li_List = tree.xpath(//section【@class = list】/div)
fp = open(58.txt,w,encoding=utf-8)
for li in li_List:
title = li.xpath(./a/div【2】//div/h3/text())【0】
print(title)
fp.write(title+\n)
- 正则表达式 (解析页面)
- 通过网页请求requests返回的数据取得text文本内容
- 通过python的re 正则库,可以对文本内容进行正则匹配从而解析到想要的数据内容
- BeautifulSoup4 (解析页面)
- BeautifulSoup也是python的一个库,类似于xpath同样是对页面进行解析,实现原理有所不同,它是基于DOM的,解析后可以按照DOM树对页面进行提取数据,懂得css等前端技术的人用起来会更顺手,且相对于xpath要API非常人性化,支持css选择器
- 灵活性和性能来说bs4没有xpath好用
- 文档传送门: https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
- Selenium: 它本身是Web应用程序测试的工具,直接在浏览器中运行, 所以它可以做到像浏览器一样把数据全部都加载出来,这样一来哪怕是动态加载也是可以拿到加载后的数据的。它本身是专门针对测试的工具 ,所有还是测重测试方向,官网传送门: https://www.selenium.dev/;而python调用selenium的API文档可以在这里看到 https://selenium-python.readthedocs.io/ 网站中有详细的说明以及对Drivers的下载链接地址。
- Scrapy 分布式爬虫框架,
主要步骤: 创建工程、爬虫文件、执行
- scrapy startproject xxxPro
- 在项目目录下输入: scrapy genspider spiderName www.XXX.com 创建爬虫文件
- 框架会自动创建所有需要的items pipline settings.py 中间件等默认文件,而开发者只需要去根据需求去修改对应的文件来完成整个爬虫任务的构建即可
- 在项目目录下执行: scrapy crawl spiderName