1、一些问题
- 编译的源码来源于什么地方?
- 如何知道互相兼容的版本号?
- 用什么工具编译?和辅助的工具有哪些
- 编译有bug时如何快速定位到问题? 如果解决问题
2、编译的版本
Hadoop: 3.1.3
hive : 3.1.3
spark: 3.1.3
* 为什么都选择3.1.3,在hive 的官方地址,是有如下图说明的,那我们就默认hive3.1.3和hadoop3.1.3是完全兼容的(实际上是有bug的);以这两个版本的Hadoop和hive搭建的集群在启动hive的时候会报兼容性错误。

实际上,我们要编译的组件一般不会是hadoop ,多数情况是hive,spark等组件,主要是因为这些组件如果基于Hadoop生态的运行的话,那都是这些组件去兼容Hadoop,故我们这里是主要编译hive。
也就是我们第一点的基本思路是: ”先明确hive的版本,同时希望这个版本的hive去兼容某个版本的Hadoop“
3、寻找源码
源码基本上都是去GitHub上的maven仓库里找
地址:https://github.com/apache/hive 或者 https://gitee.com/apache/hive
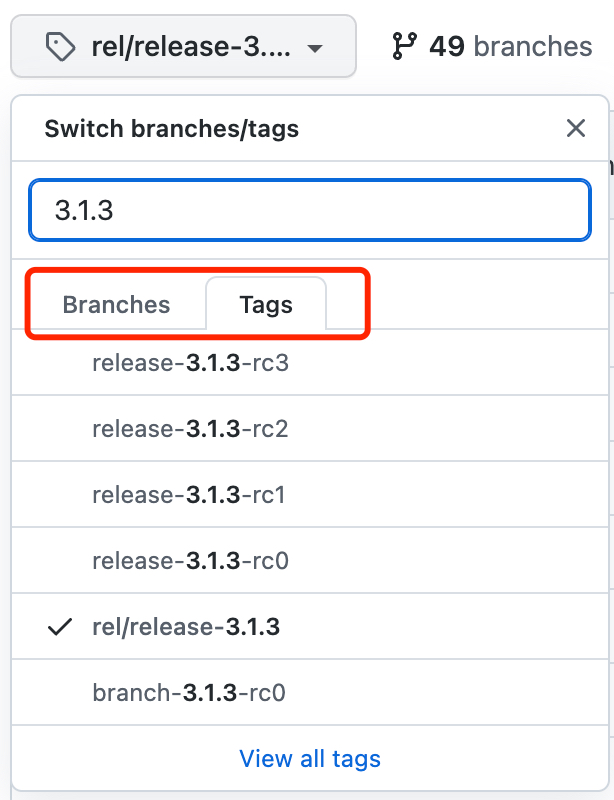
此地址看到的hive的master分支,我们可以点击master的下拉框,然后输入我们的版本号,注意我们要编译的是具体的版本不是分支,所以要搜索tags,搜索后如下图。这个时候其实主要是搜一下看看有没有我们要编译的版本以及该版本下对应的其它组件版本号
切换到该版本后,找pom.xml文件,点击打开;我们可以直接在打开的页面搜索 hadoop ,多找一下就会发现hive3.1.3对应的Hadoop版本其实是 <hadoop.version>3.1.0</hadoop.version>,也就是我们之前所说的,如果把hive3.1.3放在hadoop3.1.3上搭建环境,大概率会出现问题的。
4、配置环境
- MacBook Pro (13-inch, M1, 2020), macOS Monterey
- java: jdk1.8.0_212
- maven: Apache Maven 3.8.6
- IntelliJ IDEA 2022.2.2 (Community Edition)
- git version 2.37.3
4.1 idea git 插件下载源码
- idea 打开后 通过 Get from CVS的方式,填入github上hive的地址
- 下载后在idea的右下角master的地方点一下,然后点击 。 checkout tag or version,输入3.1.3我们需要的版本点击确定。则branch就切换到该版本了。
- 无论是 master分支还是我们想要切换的分支遇到提示 。 reload maven projects 的弹出框都点击yes
- 此时刷新maven插件,基本上大概率是会报错的。不管是 pentaho-aggdesigner-algorithm:pom:5.1.5-jhyde 和ldap-client-api:pom的哪一个错误,我们去搜索资料都能找到一些解决方案,但是基本上都是不可用的。
- 为什么说报错在此篇文章书写时没法解决,主要是因为maven的问题,maven此时是最新版,而且从3.8.1开始maven block掉了所有HTTP协议的repositories,所以针对前边提到的各种错误,不管搜到什么答案,大概率都是没法有效解决的。笔者的处理方案是手动下载一个maven的tar包,配置一个maven3.6.3的版本,也就是次新的大版本
- 刷新maven插件,基本上不会报错了;在Terminal输入 。 mvn clean package -Pdist -DskipTests -Dmaven.javadoc.skip=true,回车编译来验证当前的3.1.3版本是否有问题。
4.2 遇到的错误
| Could not find artifact org.pentaho:pentaho-aggdesigner-algorithm:pom:5.1.5-jhyde in nexus-aliyun |
| 网上多数说是增加阿里云的spring- plugin的依赖,但是实际上没有效果,主要是此时的spring- plugin依赖里也没有这个jar包,需要增加spring自身的仓库支持 |
| https://www.codeleading.com/article/91364854522/ |
| Failure to find org.glassfish:javax.el:pom: |
| 此问题可以在此处不关注它, |
| idea maven 一直报错“Could not transfer artifact |
| 也可以不关注此问题,但是有专门的此问题场景解决方案 |
| https://blog.51cto.com/u_15162069/2804511 |
| Blocked mirror for repositories |
| 最新版本的maven block掉了所有HTTP协议的repositories,仅支持https;maven次新大版本是3.6.3,是不会出现这个问题的。所以手动降版本,这也一下解决好几个问题 |
| https://www.jianshu.com/p/274a45a2db05https://blog.csdn.net/qq_41980563/article/details/122061818 |
5、修改Hadoop版本号及处理报错
- 视频教程里 : https://www.bilibili.com/video/BV1x14y177Ab?p=7&vd_source=b2e82cf2c96f0ecd7432e09d95d7d8ec 直接在集群中调用hive触发里问题,从而快速的找到了主要兼容的jar包,但是一般我们习惯性直接将hive源码的pom文件hadoop设置成我们希望的版本 3.1.3,直接编译,笔者尝试过,直接改 Hadoop3.1.2 这样编译时不出现问题。
- 笔者并没有完全直接去修改主要的兼容报错的jar包, 在编译时遇到了各种报错,笔者没有采用视频摘樱桃的方式,而是逐一来修改涉及到的代码
- java的某个类或者方法开始计算停用的时候会在官方API文档中开始做上 。 Deprecated 标记,有这个单词的方法说明官方在通知各位这个方法要做好放弃的准备了,它一般也同时给出解决方案和停用大概时间
6、修改的java文件及主要问题
- 组件版本升级时涉及大到代码适配的工作,主要就是针对代码中的错误,去定位对应包中类的方法是在什么时候做出来了改变,而官方的API文档中都会有相应的痕迹,耐心的去文档里大版本的对应着找一找就可以找到了。(所谓大版本,就是类似于1.0,2.0,而中间的1.01,1.02 这些可以暂时跳过,除非某两个大版本相应的方法直接发生了变化,这时需要细化中间的小版本来看一下具体的情况,但一般都是大版本发布某方法要被弃用了,替换了的声明)
- 有时候,你不需要去懂怎么回事,只要找到关键位置,照葫芦画瓢的做就好了
- 其实要修改的还有很多地方,因为hive有很多的 module,每个module都可能指定不同的版本,而只有在某些特定场运行时的场景下才可能触发bug,但是现在编译确实是能通过。其它具体的问题就得去进一步慢慢验证修复
| [ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.6.1:compile (default-compile) on project hive-druid-handler: Compilation failure[ERROR] /Users/ethan/IdeaProjects/hive/druid-handler/src/java/org/apache/hadoop/hive/druid/serde/DruidScanQueryRecordReader.java:[46,61] <T>emptyIterator()在com.google.commn.collect.Iterators中不是公共的; 无法从外部程序包中对其进行访问 |
| import java.util.Collections;// 替换了如下的代码// private Iterator<List<Object>> compactedValues = Iterators.emptyIterator(); private Iterator<List<Object>> compactedValues = Collections.emptyIterator(); |
| 此问题找解决方法的过程是视频中说的方式,去API文档找报错的方法是在什么时候开始过渡停用的。整个修改的思路是差不多的,单独列出来这个是除了这个类,其它的修改基本上都是一样的方法,一样的处理方式 |
| git status刷新索引: 100% (17020/17020), 完成.位于分支 my-hive-3.1.3尚未暂存以备提交的变更: (使用 “git add <文件>…” 更新要提交的内容) (使用 “git restore <文件>…” 丢弃工作区的改动) 修改: druid-handler/pom.xml 修改: druid-handler/src/java/org/apache/hadoop/hive/druid/serde/DruidScanQueryRecordReader.java 修改: llap-common/src/java/org/apache/hadoop/hive/llap/AsyncPbRpcProxy.java 修改: llap-server/src/java/org/apache/hadoop/hive/llap/daemon/impl/AMReporter.java 修改: llap-server/src/java/org/apache/hadoop/hive/llap/daemon/impl/LlapTaskReporter.java 修改: llap-server/src/java/org/apache/hadoop/hive/llap/daemon/impl/TaskExecutorService.java 修改: llap-tez/src/java/org/apache/hadoop/hive/llap/tezplugins/LlapTaskSchedulerService.java 修改: pom.xml 修改: ql/src/java/org/apache/hadoop/hive/ql/exec/tez/WorkloadManager.java 修改: ql/src/test/org/apache/hadoop/hive/ql/exec/tez/SampleTezSessionState.java |
| 以上是所有修改的地方,pom文件的修改主要是修改guava的版本号 |
7、替换spark
先修改pom文件,替换spark的版本,spark3.x 对应的Scala版本最低是2.12,所以同时把Scala的版本也修改掉,可能有读者会问,怎么知道Scala也得变的,不要etc,自己去官方文档看一下基本的要求就知道了。
| <spark.version>3.1.3</spark.version><scala.binary.version>2.12</scala.binary.version><scala.version>2.12.10</scala.version><SPARK_SCALA_VERSION>2.12</SPARK_SCALA_VERSION> |
然后继续在Terminal通过命令: mvn clean package -Pdist -DskipTests -Dmaven.javadoc.skip=true, 来从新编译,笔者遇到了大致三个问题
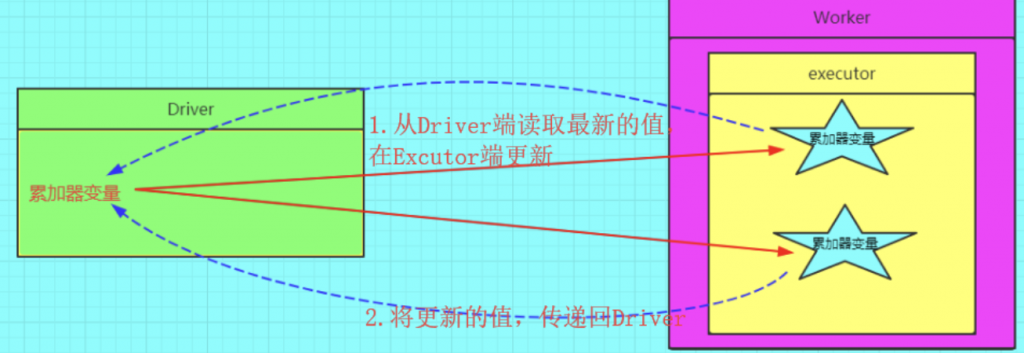
7.1 SparkCounter 中累加器的修改
这里主要是设计到spark自定义累加器实现的继承类替换问题。具体远离参考 spark 累加器学习随笔
7.2 ShuffleWriteMetrics.java 报错
| metrics.shuffleWriteMetrics().ShuffleBytesWritten()不存在,从名称看类似的方法为bytesWritten()metrics.shuffleWriteMetrics().ShuffleWriteTime()同样不存在,修改为writeTime() |
| public ShuffleWriteMetrics(TaskMetrics metrics) { // metrics.shuffleWriteMetrics().ShuffleBytesWritten()不存在,从名称看类似的方法为bytesWritten() // metrics.shuffleWriteMetrics().ShuffleWriteTime()同样不存在,修改为writeTime() this(metrics.shuffleWriteMetrics().bytesWritten(), metrics.shuffleWriteMetrics().writeTime()); } |
7.3 找不到spark_project
编译报错提示org.spark_project.guava····· 不存在,找到相关报错的java文件,修改import org.spark_project.guava.collect.Sets;为 import org.sparkproject.guava.collect.Sets;。保存后,重新安装依赖