python stock 量化投资和股票分析,python的numpy、pandas包写上几行代码,再用matplotlib画上几张图,用sklearn(scikit-learn)包的模型画个传统机器学习的模型又或用tensorflow或者pytorch等框架套入深度学习,云云如是
python stock 这两个词原本是互不相干的,不知具体从何时起,量化投资 、股票分析 、数据模型 、python数据分析 等等各种词汇的联系越来越多,从而使得很多所谓的交易高手 、股市技术流 、股票大佬 在各个平台来吹嘘自己的交易策略有多么的厉害。numpy 、pandas 包写上几行很多小白看不明白的代码,再用matplotlib 画上几张图,就说自己的交易策略;稍微知道的多就会在用sklearn (scikit-learn )包的模型画个传统机器学习的模型;再厉害一些的呢就用tensorflow或者pytorch等框架套入数据做个深度学习的模型,云云如是… 基本的教学大纲差不多是下边这样的。
python stock 股票数据来源
合法爬虫 现成的python包数据调用,如yfinance 臆想出来的 雅虎的yfinance还是很好用的,如果读者没法使用就可以参考笔者之前的爬虫文章去正规的网站上爬取股票数据,至于怎么做到合法呢?就是看网站域名下的robots.txt文件是什么样的,比如很多人都是知道的东方财富网,我们直接在它的根域名后边跟一个robots.txt,在浏览器地址栏中加载看一下
https://www.eastmoney.com/robots.txt
而浏览器加载的结果如下,我们看到User-agent没有具体的指向,并且Disallow 又没有说不允许谁来爬,所以呢爬TM的没问题。
User-agent: *
Allow: /
Sitemap: http://www.eastmoney.com/sitemap.xml
数据初探和哔哩哔哩
如上文所说我们用yfinance加载数据,用特斯拉 (TSLA )的日交易数据来演示一哈。
import yfinance as yf
tsla= yf.Ticker("tsla")
data = tsla.history(start="2020-06-01", end="2022-06-30", interval="1d")
print(data.head(2))
print(data.columns)
Date Open ... Dividends Stock Splits
2020-06-01 2020-06-01 00:00:00 171.600006 ... 0 0.0
2020-06-02 2020-06-02 00:00:00 178.940002 ... 0 0.0
Index(['Date', 'Open', 'High', 'Low', 'Close', 'Volume', 'Dividends',
'Stock Splits'],
dtype='object')
到了这里大佬们会比哔哩哔哩一下这些数据都是啥,比如这些数据的含义啊,什么日开盘价、收盘价、交易量等等,然后会在介绍一下,要用什么来计算指标,然后又用这些指标来达到什么样的效果。自己知道且有耐心的老师还会给说一下这些指标具体的数学本质是啥。
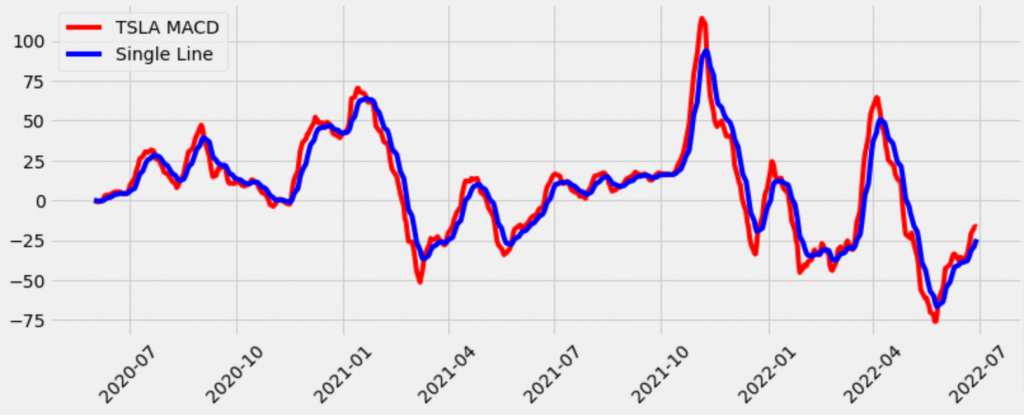
matplotlib画个MACD图
先计算上线布林线,整个过程都是pandas dataframe的常规计算,没有什么特殊的,如果非要摆一摆就是把这个MACD的含义啊,pandas的使用啊,数学意义啊,股市指标价值啊,巴拉巴拉讲上几节课。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('seaborn-colorblind')
# 短线EMA
shortEMA = history.Close.ewm(span=12, adjust=False).mean()
# 长线EMA
longEMA = history.Close.ewm(span=26, adjust=False).mean()
# MACD
MACD = shortEMA - longEMA
single_line = MACD.ewm(span=9, adjust=False).mean()
plt.figure(figsize=(12.2, 4.5))
plt.plot(history.index, MACD, label='TSLA MACD', color='r')
plt.plot(history.index, single_line, label='Single Line', color='b')
plt.xticks(rotation=45)
plt.legend(loc='upper left')
plt.show()
MACD线 mplfinance 画个K线图
malfinace 本身以前是matplotlib的一个模块,但是从19年开始独立出来了,所以读者如果用的是较新的python环境必须的从新安装一下,模块也好,包也罢都可能会是另一个知识点,因为小白们是不知道怎么用这些工具的,得学啊。
==================================
WARNING: `mpl_finance` is deprecated:
Please use `mplfinance` instead (no hyphen, no underscore).
To install: `pip install --upgrade mplfinance`
For more information, see: https://pypi.org/project/mplfinance/
======================================
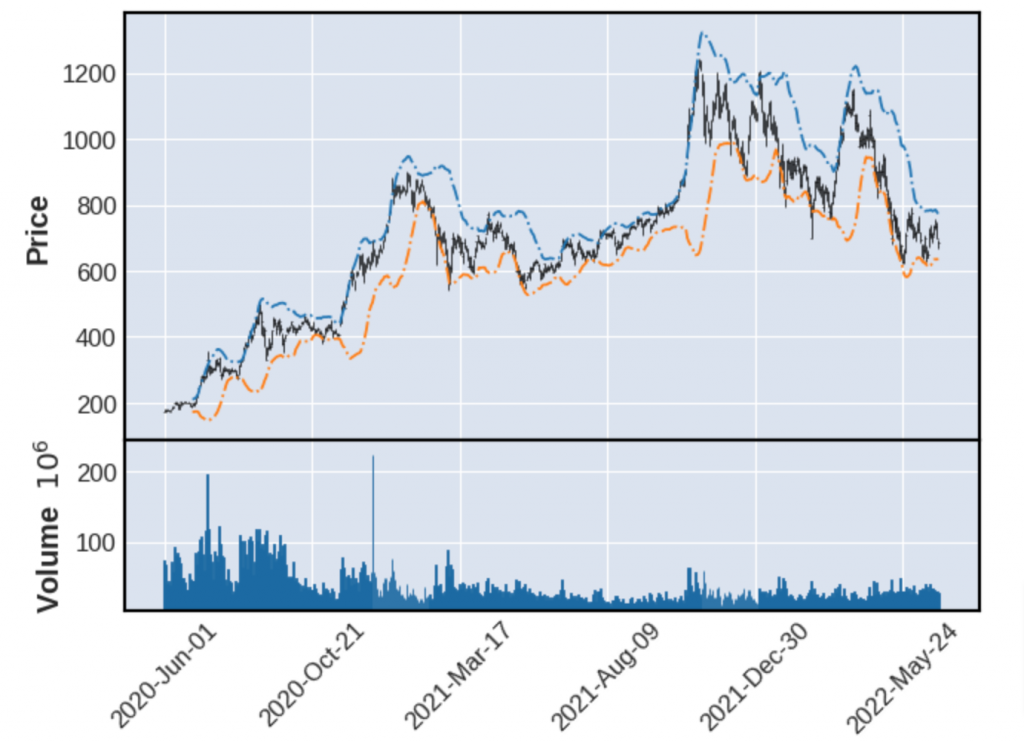
BOLLING 计算
data['SMA'] = data['Close'].rolling(window=20).mean()
# 计算 standard deviation
data['STD'] = data['Close'].rolling(window=20).std()
data['UpperLine'] = data['SMA'] + (data['STD'] * 2)
data['LowerLine'] = data['SMA'] - (data['STD'] * 2)
add_plot = mpf.make_addplot(data[['UpperLine', 'LowerLine']],linestyle='dashdot')
mpf.plot(data, addplot=add_plot, type='ohlc', volume=True)
机器学习做个模型吧
嘿嘿嘿,笔者不想在此篇文章里写模型的代码了,至此算是骗个炮吧:stuck_out_tongue_winking_eye:,以后空了再来后续骗。