windows anaconda 移动位置 (windows10 从C盘移动到D盘),再具体一些笔者的情况是:anaconda在window10的环境下,从C盘迁移到D盘,基本的操作跟大家搜索其它教程都差不多,而且笔者也是参考了其它很多的教程。只是,笔者有一些地方与其它教程有出入。特此记录
Anaconda的环境安装和虚拟环境的创建,在本站以前的文章中有具体的说明,此处不再复述。
迁移
直接在C盘找到anaconda的安装目录,将整个文件剪切到D盘。如笔者直接把 anaconda3这个文件夹放在了D盘的根路径下,这样的路径就是 D:\anaconda3,笔者的整个文件夹总的容量已经达到40多G了….
后续问题
不修改环境变量
有很多博文到了这一步是让读者去修改环境变量,但是笔者并没有修改环境变量,因为在环境变量里压根就没有anaconda的任何信息
修改environments.txt
environments.txt 一般是存放虚拟环境路径的文件,它一般在C:\Users\usrname\.conda的路径下,笔者把它们都修改成了anaconda3移动到D盘后的位置。修改后如下
D:\anaconda3 D:\anaconda3\envs\python3.6 D:\anaconda3\envs\python3.5 ... D:\anaconda3\envs\spider D:\anaconda3\envs\gpt2
修改电脑开始菜单快捷方式
电脑开始菜单的快捷方式在我们移动完anaconda3文件夹之后就已经完全失效,不能再打开了,点击的时候可能会出现如下的一些错误
- 快捷方式已经失效是否删除
- This application failed to start because no Qt platform plugin: 这是运行Anaconda Navigator报错
- conda : 无法将“conda”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。 这是运行Anaconda PowerShell Prompt报错。
以上三个问题是迁移后的主要问题,其它很多的附带问题都可以通过解决这几个问题来得到附带处理掉。而快捷方式失效是首要需要解决的问题。
让快捷方式可以生效的解决方案,笔者参考了《windows下将Anaconda从C盘迁移至D盘(其他盘)》博文的内容,主要借鉴的是就是在新的anaconda目录下执行以下命令,来使得快捷方式能找到新的目录位置,操作如下:
- 进入D:\ananconda3。在此路径下打开cmd dos命令窗口–如果渎职无法在cmd命令窗口进入到D盘可以参考《win10如何做到在指定目录下打开cmd命令窗口》对cmd窗口权限进行修改。
- cmd命令窗口确定进入到D:\anaconda3路径后,输入以下命令,因为此时我们的环境已经混乱了,所以直接就用anaconda路径里存的python可执行脚本来执行命令
python.exe .\Lib\_nsis.py mkmenus
命令执行之后,快捷方式就可以点击了,且不再提示快捷方式失效的。此时开始报错…..
Anaconda Navigator 运行报错的处理方案笔者主要是参考了《运行Anaconda Navigator报错:This application failed to start because no Qt platform plugin》,其主要的处理思路就是:
把Anaconda路径下的 platforms 拷贝出来
.\Anaconda3\pkgs\qt-**\Library\plugins目录下的platforms文件夹复制黏贴到Anaconda的根路径下,例如笔者并没有完全按照参考把qt-5,9,7**的platforms拷贝出来,而是拷贝了最新的qt-5.12.9**里的,如何判断最新可以从时间上看,但是时间如果有些迷惑你的话就直接把qt后边数字大的platforms拷贝到anaconda根路径下,如笔者的拷贝完就是 D:\anaconda3\platforms

到了这一步,电脑开始菜单里的 Anaconda Navigator快捷键就应该可以用了。
接下来是 电脑开始菜单 Anaconda PowerShell Prompt 快捷方式的处理,现在点击它应该还在报错。但是我们不要去点击,直接在快捷图标上 右键 –>(更多) –> 打开文件夹位置,一般会在类似路径下C:\Users\username\…\Microsoft\Windows\Start Menu\Programs\Anaconda3 (64-bit),看到如下文件;直接在文件上 右键–> 属性

直接在文件 Anaconda Powershell Prompt文件上 右键–> 属性,弹出如下图,我们直接将快捷方式 -目标 的值拷贝出来, 就会看到这个目标要执行的命令, 而命令中涉及到的路径还是anaconda在C盘时的路径 ,我们要把它们修改成现在的anaconda路径地址。
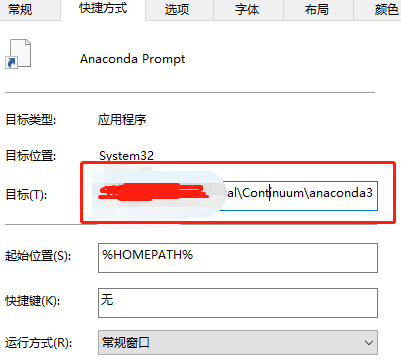
# 属性目标值修改前 %windir%\System32\WindowsPowerShell\v1.0\powershell.exe -ExecutionPolicy ByPass -NoExit -Command "& 'C:\Users\...\AppData\Local\Continuum\anaconda3\shell\condabin\conda-hook.ps1' ; conda activate 'C:\Users\...\AppData\Local\Continuum\anaconda3' " # 属性目标值修改后 %windir%\System32\WindowsPowerShell\v1.0\powershell.exe -ExecutionPolicy ByPass -NoExit -Command "& 'D:\anaconda3\shell\condabin\conda-hook.ps1' ; conda activate 'D:\anaconda3' "
我们从上边修改的命令中可以看到一个叫做conda-hook.ps1的文件,这个文件的内容也是需要改的,不然依旧会报错。修改的内容依旧是路径,读者去自己的anaconda文件夹对应的目录下,找到这个文件打开它编辑就可以看到了,所有的路径都改。
至此,整个anaconda迁移工作就算是完成了,当然如果读者在别的IDE中有引用anaconda环境的话需要去对应的IDE做调整即可。笔者建议读者修改完后,把Anaconda Navigator打开,每个虚拟环境都点一点,让它自己刷新更新一下。